

【核心技术】量化交易系统中,把策略和行情交易进程分离,使用共享内存通信,有什么利弊?
yizhi/核心开发
首先如果题主只是个人交易者或者小的团队,那建议就不必考虑自己从零写了,远离痛苦,不如好好研究策略,直接用vnpy或者其他开源的交易系统,最多花点小钱,相信我,值得(这个行业不存在什么“见不得人”的“核心科技”,只有无穷无尽内核层跟业务层的屎要处理)
如果题主是一个私募或者机构的开发,做出来的交易系统是给其他人使用,那我就能假设题主做出来的成品服务时间十年起步,且即使题主现在只有一个人独自成队,在未来也会至少拥有三到五个同伴的开发队伍,咱们从这个角度讲一下交易系统的开发
我们做好了场景的约束:
- 维护十年的系统,业务会不断迭代(增加)
- 多人的团队
- 开发跟交易员不是一波人
- 量化业务不像互联网流量这么大,但对低延迟(tick to trade)要求极大,想尽办法榨干cpu
- 稳,准,快,是交易系统三大核心,稳(不崩)是第一位
- 信息流的时序性同样非常重要
- 实盘架构可以同时兼容回测
注:下文用 “你” 代指 “充满智慧的量化系统开发者”
阶段一:一个进程搞定所有,架构简单就是快
就像其他回答提到的,单个进程接完行情接策略,策略报单直接怼交易接口,完全没问题
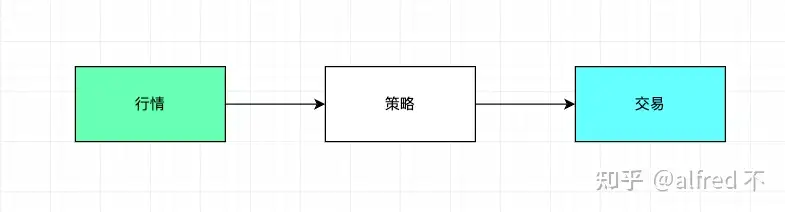
行情接完,灌到 disruptor 这样的无锁队列,策略下单再来一个 disruptor,交易读到下单,甚至策略直接接交易的接口。
这样的好处:简单,快,只要策略别进行复杂的计算,这样一定是最快的
但还是回到我们刚才说的,咱们从一个要维护十年的交易系统的角度看,这样干至少有这么几个问题
- 可维护性:你不可能只接一个行情或者交易接口(股票期货甚至数字货币,你可能全都要),不可能只用一个下单账户,如果要加接口或者策略有选择往不同账户里下单,以及之后你会遇到的“因子计算” operator 相关的业务,这种模型维护起来会比较困难
- 安全性:你不可能永远只有一个策略,怕不怕策略崩?敢不敢说 core dump is not uncertain ?崩了所有策略包括行情交易一起爆炸,原地疯狂
- 也许不那么快:+7说: 搞多线程能不能搞得定?要不要加锁?能不能避免context切换?尤其是交易系统这种复杂场景,加锁不如直接多进程;以及你进入了一个充满拷贝的世界,说拷贝对性能伤害大容易被杠,如果能轻易做到零拷贝,为何不顺手实现了
- 无法适配回测:当然你可以为了kpi单独搞一套回测系统,但追求精益求精的你肯定无法忍受回测跟实盘在两套系统里的山一般的隔阂
阶段二:多策略多进程,共享内存金腰带
你心心念念搞定了阶段一,兴奋的上线,度过了短暂的贤者peace时期,预计如果在一个不错的机构或者私募团队里,随着业务的拓展预计很快就会遇到上面的问题。于是你想到了用共享内存+多进程模型继续升级你的系统
首先你想到的会是这样一个模型
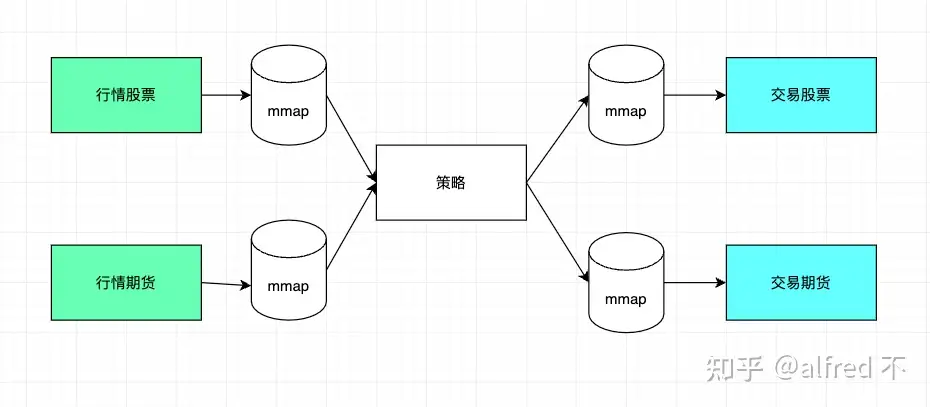
现在咱们改为多进程模型,充分保证即使一个进程挂了,其他进程还能继续while true下去(至于为什么采用多个mmap,mmap是可以多读多写,但如果不能优秀的区分mmap,也存在锁的问题,无法榨干cpu,确保每一个mmap只能单写多读,就不需要加锁,同时也很好的保证了时序性)
但上面的模型还有一个问题,mmap的建立非常复杂难以管理,进程间相互依赖(比如策略下单要依赖交易进程的运行)会成为你脱发主要诱因,于是充满智慧的你想到了用一个“daemon”进程来管理,并设计了一套协议,来解决系统资源调度(mmap建立),与进程启动对依赖进程的检测(就像tcp的三次握手),升级到以下模型
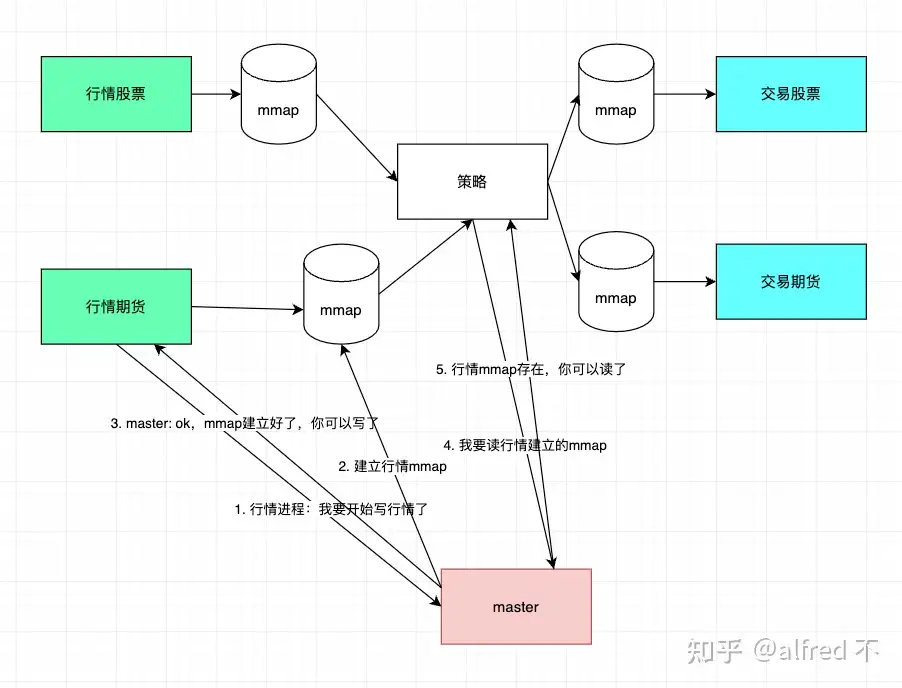
不要被这张丑图吓到,原理很简单:
行情启动时,策略未必已经运行,但没关系,行情可以开始写mmap,步骤如下
- 行情进程申请行情mmap资源
- master收到后建立资源,并告诉行情进程:资源建立好了,你可以开始写了
- 行情收到信号后,开始写mmap
同时策略启动后,经过如下步骤:
- 跟master说:我要读行情
- master确保要读的mmap已经建立,不存在的话就建立
- master告诉策略mmap已经建立,可以开始读
- 策略收到信号,开始读属于行情进程的mmap文件
这样进程启动(行情/策略/交易)间的依赖关系就被解耦了,即使行情/交易没启动,策略启动了,最多就是读不到数据,也不会出什么问题,等到行情/交易启动后,即可通知master“我启动了”,然后master向外广播,这样策略也可以根据依赖进程的启动停止做出相应操作
阶段三:各种服务稳定运行,实盘回测一体化,业务屎山吃的多了就成为坚固的护城河
你费时一年,设计了协议,完成了一个可以支持多个策略,多个交易接口/行情接口的,量化系统初级模型,兴奋的上了实盘,一切符合预期,又快又稳,领导一拍大腿连连称赞小伙子前途无量,于是你的业务吃屎生涯开始展开
- 1万个策略,每个策略启动后,持仓资金这些东西总不能每次都请求,要请求一万次说不过去,当然你可以选择用一个sql之类的做存储,但现在你有了共享内存 — 这个时候你需要一个进程缓存交易进程启动后拉下来的各种数据,静态数据,持仓/资金数据,当新的策略启动后,可以从这个缓存进程内拉取最新的持仓数据,我们管这个缓存进程叫ledger
- 每个策略会有一些基础因子,比如k线也就是bar,你肯定不能在每个策略内把相同的逻辑实现一遍 — 这个时候你想到搞一个专门的进程group,叫做算子
- 这个交易系统不能光下单吧,还得做持仓管理跟资金计算吧,期货保证金,两融计算两座大山,更别提数字货币持仓量一个int64_t未必能放得下,需求来了不能推吧
- 共享内存可以留痕,你想到用这个可以实现回放,并整出前端工具让交易员导出实盘数据做复盘,精益求精,卷上加卷,人和人的差别在晚上8点后,交易员跟交易员的差别在15:30收盘后(此句纯属扯淡)
- 共享内存内存连续,读性能物理级别最快,你想到用这个可以实现高性能回测,起一百个回测调参,还是逐笔回测,牛逼哄哄,领导又拍大腿介绍表妹跟你相亲
于是你的架构变成了这样
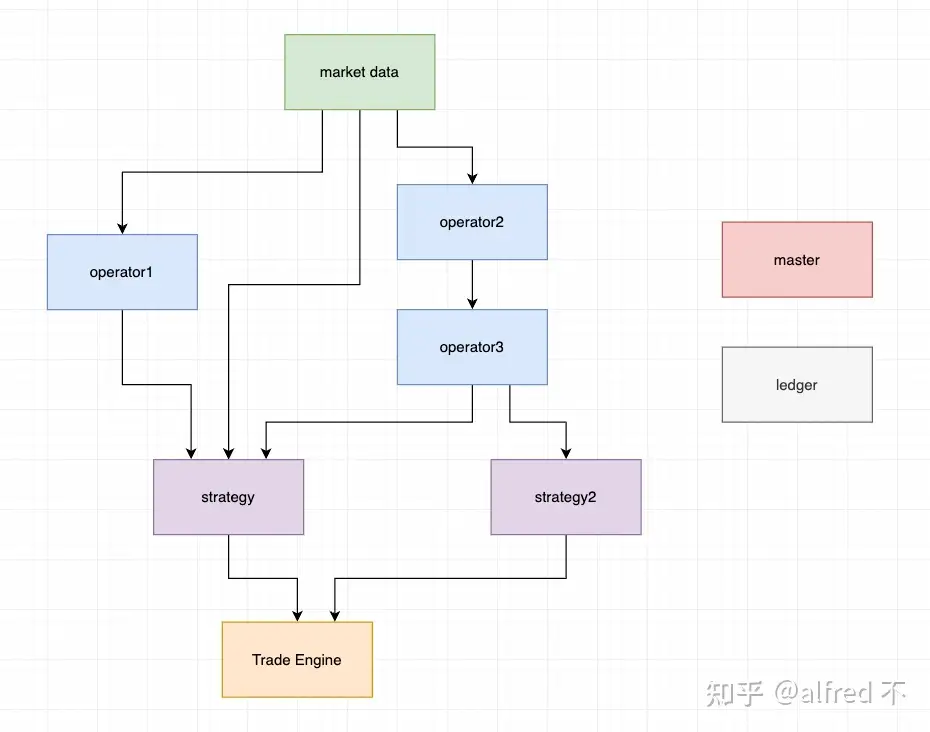
由此,通过mmap,你享受到了一套框架,拥有良好的鲁棒性,可拓展性,零拷贝,低延迟,且实盘回测同时兼容的众多feature
此刻的你已然升华,事了拂衣去,转身赚大钱
阶段四:系统优化,May the force be with you
- 我在其他回答里也提到,mmap换页的时候开销异常大,作为有追求的你,肯定会处理好异步预加载与异步flush
- context切换对低延迟系统来说乃万恶之源,以上模型可以做到系统级别不加锁,但你的进程数量不应该超过系统核数,不然你不知道cpu会怎么调度,同时上绑核跟开大页
- 行情接口跟下单接口因为网络通信,必然会涉及context切换,你大概率搞不定裸接口,但是你可以搞定网卡,如果有实力,在网卡上做优化也可以帮助你减少延时,以及fpga可以帮助解放些cpu资源,去找对应的柜台商吧,接口的事情交给专业的人。 ps. 以上模型帮你避免了策略收到行情/交易context切换的影响
- 量化交易系统开发的核心就是每个进程一个while true,cpu永不眠
- 以上模型可以帮助你实现单次通信2微秒以内,从行情到交易,5微秒内(不考虑业务,1微秒内都可以,但业务总会加,头发总会少,人也会变老)
- 最后,当你费劲心机将交易系统延迟优化到极致,兼顾业务复杂性跟内核的鲁棒迅捷,就会有一堆人跑来告诉你,“交易系统延迟无所谓,最关键的是网络延迟,网络延迟50ms,交易系统1微秒还是10微秒的区别意义不大”,这个只能说,专业的业务都是要追求极致,没有所谓“无所谓“